






随着大数据时代的到来,实时数据处理与分析变得越来越重要,Kafka作为一种分布式流处理平台,广泛应用于实时数据处理场景,在某些情况下,我们也需要关注Kafka的非实时API,以便更好地利用Kafka的功能,本文将详细介绍往年12月27日Kafka非实时API的应用与解析。
Kafka简介
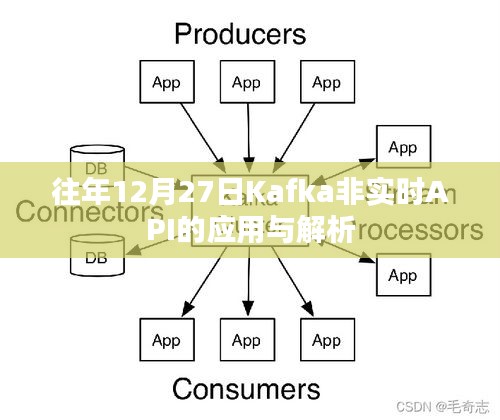
Apache Kafka是一个开源的、分布式的、高吞吐量的流平台,它可以处理实时数据,并在分布式系统中提供高吞吐量的数据传输能力,Kafka提供了多种API,包括实时API和非实时API,以满足不同场景的需求。
Kafka非实时API概述
Kafka非实时API主要用于处理非实时数据或批量数据,与实时API相比,非实时API更注重数据的批量处理和存储,这些API通常用于处理那些不需要立即响应的数据,如日志数据、事件数据等,非实时API允许我们在后台进行数据处理,从而提高系统的稳定性和性能。
四、往年12月27日Kafka非实时API的应用
在往年12月27日,Kafka非实时API已经广泛应用于以下场景:
1、批量数据处理:非实时API可用于处理大量数据,如日志数据、审计数据等,这些数据可以在后台进行批量处理,以提高系统的性能和稳定性。
2、数据集成:Kafka非实时API可以与各种数据源进行集成,如数据库、文件系统等,通过将这些数据源的数据导入Kafka,我们可以实现数据的统一管理和分析。
3、数据仓库:Kafka非实时API可用于构建数据仓库,将数据从源系统导入目标系统,在这个过程中,我们可以对数据进行清洗、转换和加载,以便更好地满足业务需求。
4、延迟处理:在某些情况下,我们需要延迟处理数据,我们需要等待一段时间来收集更多的数据或等待某个事件发生后进行处理,Kafka非实时API可以满足这种需求,实现数据的延迟处理。
五、往年12月27日Kafka非实时API的解析
在往年12月27日,Kafka非实时API的使用主要涉及以下几个关键步骤:
1、数据生产:使用Kafka的非实时API将数据发送到Kafka集群,这些数据可以是文本、JSON等格式。
2、数据消费:通过Kafka的非实时API从Kafka集群中消费数据,消费者可以订阅一个或多个主题,并获取这些主题中的数据。
3、数据存储和处理:使用非实时API将数据存储到指定的位置或进行批量处理,这可以包括数据的清洗、转换和加载等操作。
4、监控和管理:使用Kafka提供的工具和管理界面来监控和管理非实时API的使用情况,以确保系统的稳定性和性能。
Kafka的非实时API在数据处理和分析领域具有广泛的应用价值,通过了解和使用这些API,我们可以更好地利用Kafka的功能,实现数据的批量处理和存储,在往年12月27日,Kafka非实时API已经应用于多个场景,如批量数据处理、数据集成、数据仓库和延迟处理等,为了更好地使用这些API,我们需要掌握其关键步骤,包括数据生产、消费、存储和处理以及监控和管理。
转载请注明来自威巍集团,本文标题:《Kafka非实时API应用解析,历年12月27日回顾》




 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...